Se a sua squad já usa IA no dia a dia, a pergunta deixou de ser “qual modelo responde melhor” e passou a ser “qual modelo aguenta mais contexto, mais ferramentas e mais responsabilidade sem desmontar no meio do fluxo”. É exatamente nesse ponto que o GPT-5.4 entra.
Na documentação oficial da OpenAI, o GPT-5.4 é apresentado como o modelo principal para trabalho profissional complexo, coding e workflows agentic. Na prática, isso muda a conversa para times web: não estamos falando só de autocomplete mais esperto, mas de um modelo desenhado para ler muito contexto, usar ferramentas e sustentar tarefas mais longas com menos perda de qualidade.
Resumo Executivo (Key Takeaways)
- GPT-5.4 foi posicionado pela OpenAI para fluxos profissionais, coding e uso agentic com ferramentas.
- O modelo combina contexto longo, suporte a ferramentas e níveis de reasoning effort ajustáveis.
- Para squads web, o ganho real aparece em tarefas longas: análise de código, refactors maiores, auditorias e mudanças multiarquivo.
- O custo é mais alto do que variantes menores, então o uso precisa ser intencional.
- O melhor cenário não é trocar tudo por GPT-5.4, e sim desenhar uma arquitetura de uso por criticidade.
O que torna o GPT-5.4 diferente na prática
A página oficial do modelo destaca três sinais fortes. O primeiro é o posicionamento explícito para “agentic, coding, and professional workflows”. O segundo é a janela de contexto de 1.050.000 tokens, que muda bastante a forma como times lidam com material extenso. O terceiro é o suporte amplo a ferramentas na Responses API, incluindo web search, file search, image generation, code interpreter, hosted shell, apply patch, skills, computer use e MCP.
Isso importa porque muitos fluxos reais em produto e engenharia não quebram por falta de inteligência isolada. Eles quebram por perda de contexto, dificuldade de usar ferramentas com consistência e falha ao manter raciocínio útil ao longo de tarefas longas.
Para times que também avaliam Claude, Gemini e fluxos conectados ao Figma no dia a dia, esse recorte ajuda a comparar papéis com mais clareza. O ponto aqui não é transformar GPT-5.4 em resposta universal, mas entender onde ele ocupa uma faixa de trabalho mais pesada quando o contexto cresce e a execução precisa ser mais estável.
Onde times web sentem o ganho primeiro
Para uma squad web, o GPT-5.4 faz mais sentido em quatro frentes.
1. Tarefas longas com muitos artefatos
Quando a mudança depende de documentação interna, design system, múltiplos arquivos, regras de negócio e histórico de implementação, a janela de contexto maior ajuda a reduzir a fragmentação. Em vez de ficar reexplicando tudo em blocos menores, o time consegue trabalhar com uma visão mais inteira do problema.
2. Fluxos com ferramentas reais
O suporte a ferramentas deixa de ser detalhe técnico e vira parte do desenho operacional. Em um fluxo mais maduro, o modelo não serve apenas para responder perguntas: ele consulta arquivos, pesquisa, executa passos controlados e ajuda a consolidar uma saída revisável.
3. Demandas mais críticas de engenharia
Refactors maiores, análises de impacto, auditorias de arquitetura, revisão de diffs extensos e preparação de mudanças entre backend e frontend são tarefas em que modelos menores podem até ajudar, mas tendem a cansar mais rápido. GPT-5.4 entra quando a margem de erro custa tempo, retrabalho e risco de regressão.
4. Trabalho profissional com gradação de esforço
A OpenAI também destaca níveis de reasoning.effort de none até xhigh. Em termos operacionais, isso permite ajustar o quanto você quer que o modelo pense antes de responder. Para rotina web, isso é útil porque nem toda tarefa merece o mesmo custo cognitivo ou financeiro.
O que isso muda no desenho da stack de IA
O erro clássico é ler a ficha do GPT-5.4 e concluir que ele deve virar o modelo padrão para tudo. Isso tende a encarecer a operação e desperdiçar capacidade em tarefas simples.
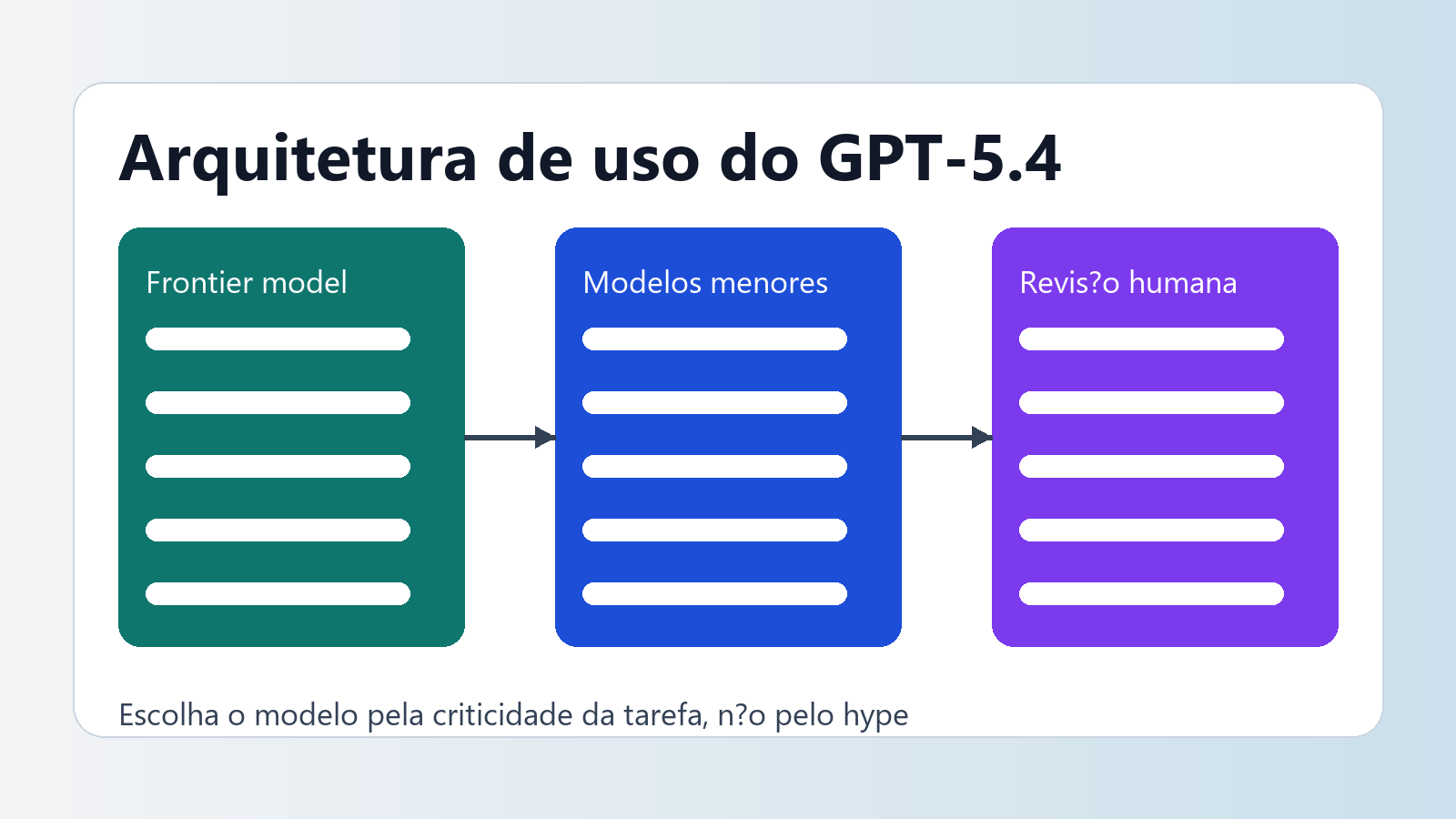
Uma arquitetura mais madura costuma ficar assim:
- modelo frontier para tarefas críticas, ambíguas ou longas;
- modelo mini ou nano para classificação, extração, triagem e subtarefas;
- regras claras para quando subir de faixa;
- revisão humana proporcional ao risco da entrega.
No próprio catálogo da OpenAI, as variantes menores da família existem justamente para cenários de velocidade, escala e custo. Então a conversa correta não é “GPT-5.4 substitui tudo?”, mas “quais partes do trabalho realmente exigem GPT-5.4?”.
Como aplicar isso sem criar caos no time
Se você quer testar GPT-5.4 com critério, comece por uma rotina recorrente que já dói hoje.
Passo 1: escolha uma tarefa longa e verificável
Boa escolha: análise de impacto de feature, refactor controlado, auditoria de componente crítico, revisão de arquitetura ou consolidação de contexto técnico antes de uma implementação.
Passo 2: defina o material que entra no contexto
Separe os artefatos certos: documentação, arquivos-chave, restrições do produto, convenções do repositório e critérios de aceite. Contexto longo só gera valor quando a seleção é boa.
Passo 3: delimite ferramentas e saídas esperadas
Se o modelo vai usar ferramentas, isso precisa ser governado. Diga o que ele pode consultar, que tipo de mudança ele pode sugerir e como a squad vai revisar o resultado.
Passo 4: meça custo contra redução de atrito
O teste precisa responder perguntas simples:
- reduziu tempo de briefing técnico?
- melhorou a qualidade da primeira proposta?
- caiu o retrabalho?
- compensou o custo?
Na prática, a decisão de manter GPT-5.4 não vem do hype da página do modelo. Ela vem do ganho operacional comparado com mini, nano ou mesmo com processos humanos sem apoio de IA.
O próximo passo para squads web
O melhor uso do GPT-5.4 em 2026 não é substituir o time, nem colocar um frontier model em toda esquina. É reservar esse nível de capacidade para trabalho profissional de verdade: tarefas longas, críticas, multiartefato e com uso controlado de ferramentas.
Se você quer testar sem bagunçar a operação, faça isso esta semana: escolha uma tarefa longa que hoje exige muito contexto, rode um experimento com GPT-5.4, documente custo, qualidade e retrabalho e compare com o seu fluxo atual. Esse é o tipo de teste que mostra valor real em vez de só gerar demo bonita.
FAQ (Perguntas Frequentes)
GPT-5.4 vale a pena para qualquer tarefa do time?
Não. Ele faz mais sentido em tarefas longas, críticas ou com muito contexto. Para rotina simples, variantes menores tendem a ser mais eficientes.
O que mais chama atenção no GPT-5.4 para times web?
A combinação de contexto longo, suporte amplo a ferramentas e foco explícito em workflows profissionais e agentic.
Qual é o jeito mais seguro de começar?
Escolher uma tarefa verificável, limitar ferramentas, manter revisão humana e comparar custo e ganho operacional com o fluxo atual.